整个以太坊p2p代码分为两部分,一部分是基于UDP的节点发现协议,另一部分是基于TCP的传输协议,我们先来看第一部分。
这部分主要代码在libp2p\NodeTable.h文件中。
节点发现协议是采用了类kademlia协议(kademlia-like protocol),关于kademlia协议可以参看wiki:
kademlia
我们先来看看NodeTable中整体的流程图: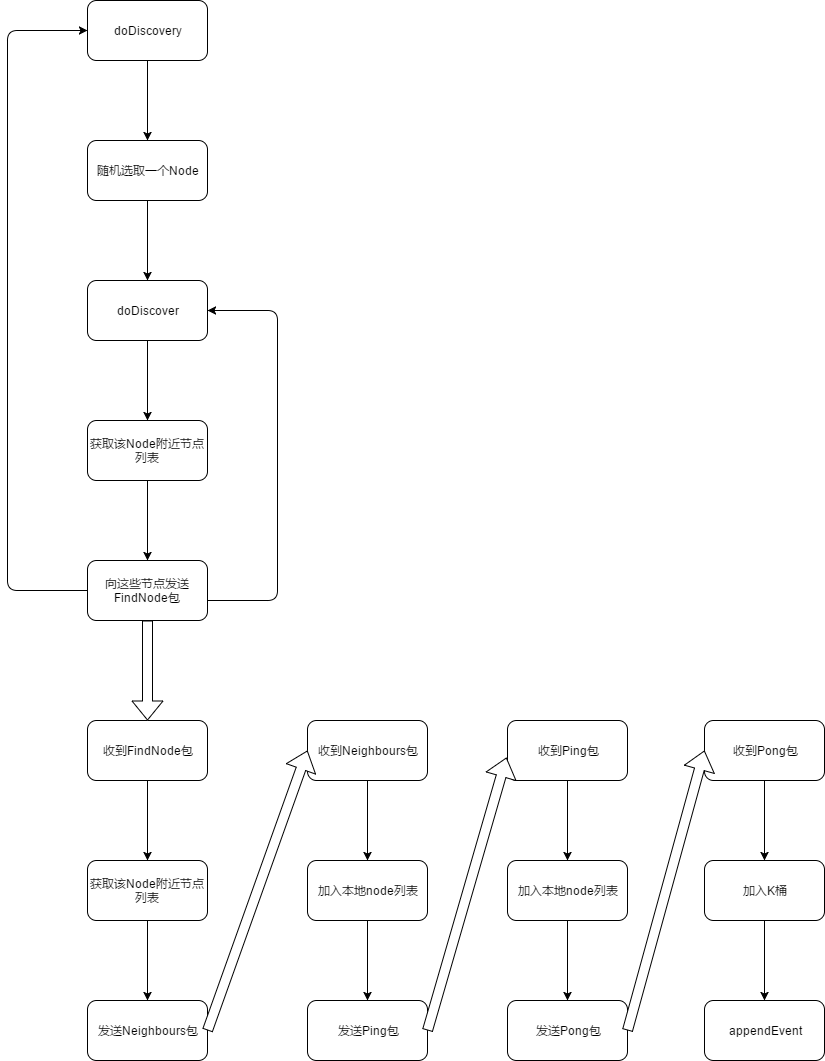
涉及到节点发现协议的四种类型数据包:
- FindNode
- Neighbours
- Ping
- Pong
#doDiscovery
NodeTable类是包含在Host类中的,Host类处理p2p模块的一个接口类,后面会谈到。我们先看NodeTable类的构造函数,里面有这段代码:
1 | m_socketPointer->connect(); |
其中第一行的connnect()函数名称有点误导,其实是socket绑定本地端口(默认端口UDP30303),并开始接收外面的数据包。
第二行的doDiscovery()函数比较重要,我们来看实现代码:
1 | m_timers.schedule(c_bucketRefresh.count(), [this](boost::system::error_code const& _ec) |
无关的代码已省略。
可以看到这个函数其实是启动了一个定时器,每隔c_bucketRefresh时间执行一个lambda函数,这个lambda函数产生了一个随机节点,并调用了doDiscover()函数。c_bucketRefresh定义:
1 | std::chrono::milliseconds const c_bucketRefresh = std::chrono::milliseconds(7200); |
得出结论,这个函数就是每隔7200ms刷新一次k桶,也就是产生一个随机节点,并调用doDiscover()。
#doDiscover
我们再来看看doDiscover()函数的实现:
1 | if (_round == s_maxSteps) |
注:这里的代码已经经过简化,省略了部分不影响理解流程的代码。
这部分代码可以分成三段,第一段和第三段代码都是用来做循环用的,并产生一个定时器,保证每隔c_reqTimeout.count() * 2时间间隔会调用一次doDiscover(),并且保证调用次数不超过s_maxSteps。
这两个常量定义如下:
1 | std::chrono::milliseconds const c_reqTimeout = std::chrono::milliseconds(300); |
第二段代码比较重要,这里涉及到了一个重要的函数nearestNodeEntries(),根据字面意思是取最近的节点列表,并向这些节点发送FindNode消息。
#nearestNodeEntriesnearestNodeEntries()函数代码:
1 | vector<shared_ptr<NodeEntry>> NodeTable::nearestNodeEntries(NodeID _target) |
同样,为了避免贴大段代码影响读者的信息,我这里做了简化,只贴出重要代码。
其实这段代码就是从K桶里把节点取出来,然后按距离从小到大排序,返回序列的前s_bucketSize也就是16个节点。这里巧妙的使用了std::map,并将距离作为key,我们都知道std::map是采用红黑树实现,节点默认会按key从小到大排列,因此把节点放到这个map里就自动排序了,免去了手动排序的过程。
这里需要注意的是距离是逻辑上的距离,并无实际意义,只是一种节点的筛选方式,我们可以看下距离的计算方式:
1 | static int distance(NodeID const& _a, NodeID const& _b) { u256 d = sha3(_a) ^ sha3(_b); unsigned ret; for (ret = 0; d >>= 1; ++ret) {}; return ret; } |
可以看到这个距离只是两个节点hash做异或,然后计算二进制最高位为1的位的位数。

